¿Cuán potentes podrán ser los modelos de lenguaje?
![]()
![]()
¿Cuán potentes podrán ser los modelos de lenguaje?
Esta es una pregunta recurrente. Las expectativas y las enormes inversiones en inteligencia artificial han despertado un gran interés por saber hasta dónde pueden llegar estos modelos de lenguaje en términos de capacidad y precisión.
En 2020, OpenAI publicó un artículo científico que analizó los factores fundamentales que determinan el rendimiento de estos modelos. El estudio concluyó que dicho rendimiento depende principalmente de tres variables: la capacidad de procesamiento, el tamaño del conjunto de datos (dataset) y la complejidad del modelo (medida por el número de parámetros).
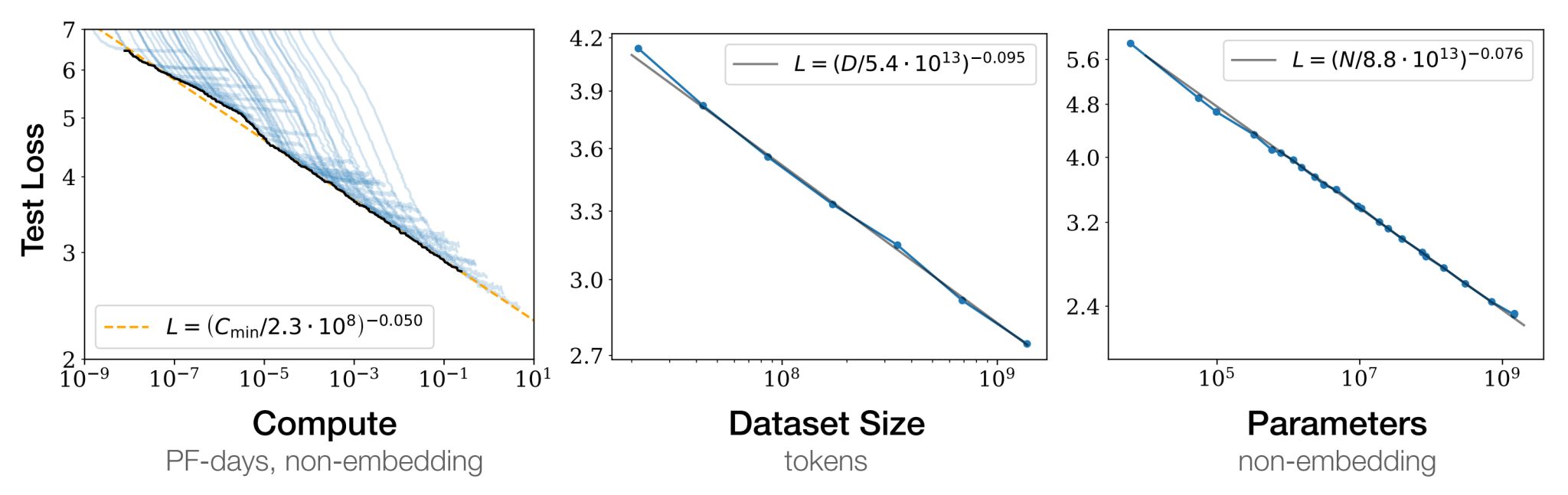
Al analizar cómo interactúan estos factores, se identifican patrones que permiten mejorar de forma óptima los modelos:
Escala sobre estructura: El rendimiento de los modelos de lenguaje depende más de la escala de estos tres factores que de la estructura interna del modelo. En otras palabras, un modelo más grande (en términos de datos y parámetros) tiende a ser más eficiente y preciso que uno con una arquitectura más compleja pero de menor tamaño. Es preferible aumentar la escala del modelo antes que complicar su diseño estructural.
Leyes de potencia: Existe una relación entre la capacidad de procesamiento, el tamaño del dataset y la complejidad del modelo. Esta relación sigue lo que se conoce como ley de potencia, lo que significa que optimizar estos tres factores de manera conjunta es esencial para alcanzar el mejor rendimiento posible. Optimizar solo uno o dos de estos factores puede llevar al sobreajuste, es decir, el modelo funciona bien con los datos de entrenamiento, pero pierde capacidad de generalización frente a datos nuevos.
Eficiencia de los grandes modelos: Los modelos más grandes resultan más eficientes incluso con menos optimización. Aunque pueda parecer contraintuitivo, el artículo demuestra que es más beneficioso entrenar un modelo grande con menos iteraciones que intentar alcanzar la convergencia en uno pequeño. En la práctica, los modelos más grandes pueden aprender más rápidamente de grandes volúmenes de datos, lo que los hace más flexibles y precisos a largo plazo.
A medida que continúe el crecimiento exponencial en el tamaño de los datasets y la capacidad de cómputo, es probable que veamos modelos de lenguaje cada vez más potentes y precisos. No obstante, también surgen desafíos importantes. Aumentar el tamaño y la complejidad de los modelos requiere enormes recursos computacionales, lo que podría limitar su accesibilidad y sostenibilidad a largo plazo.
El futuro de los modelos de lenguaje parece no tener un límite claro. Las investigaciones actuales indican que, a medida que se incrementen los datos, la complejidad y la capacidad de cómputo, los modelos seguirán mejorando hacia capacidades aún desconocidas.